杭州哪个网站建设最好新河seo怎么做整站排名
一、聚类分析与K-means的核心价值
在无监督学习领域,聚类分析是探索数据内在结构的核心技术。K-means算法因其简洁高效成为最广泛使用的聚类方法,在客户分群、图像压缩、生物信息学等领域应用广泛。其核心目标是将数据集划分为K个簇,实现“簇内相似度高,簇间差异显著”的理想状态。接下来我们将深入解析这一经典算法的原理、实现与优化技巧。
二、K-means原理与数学本质
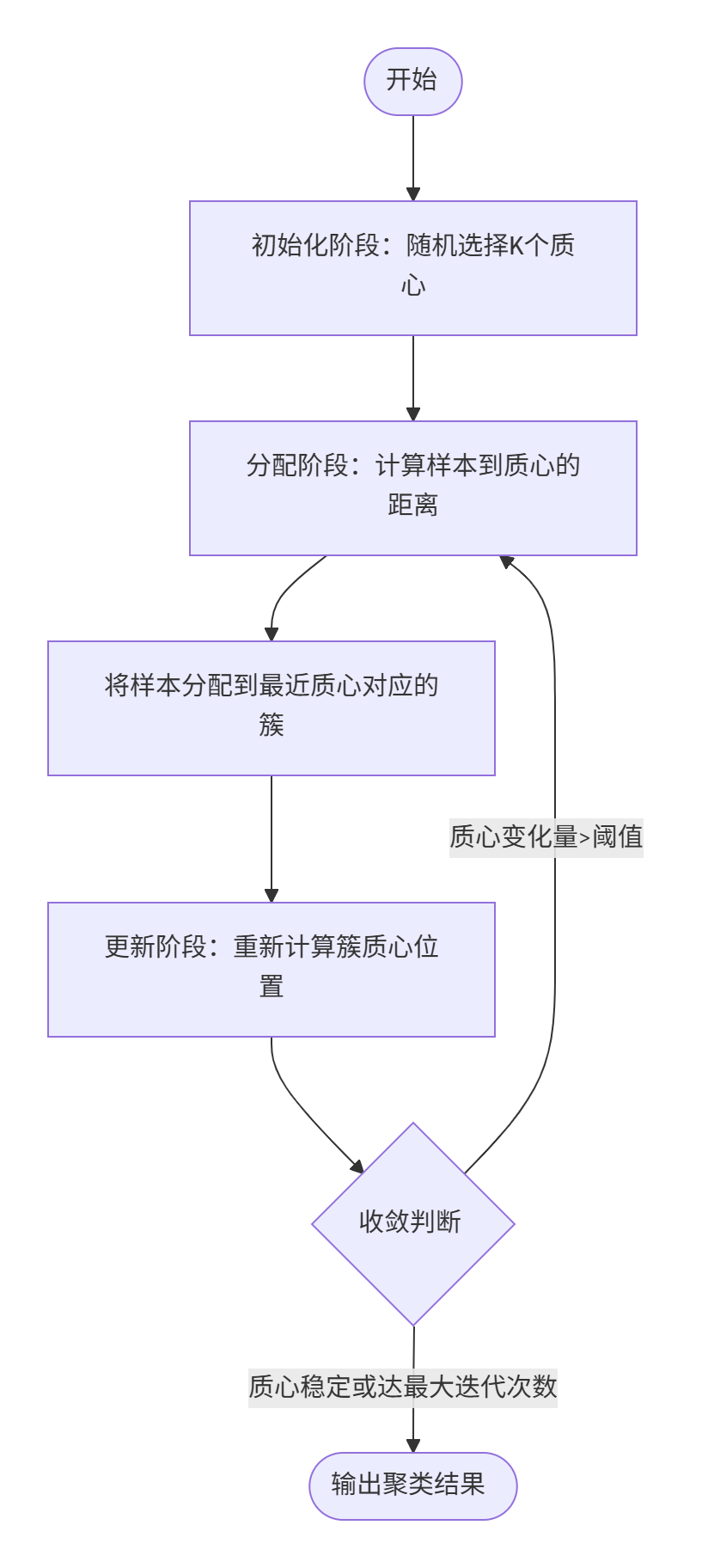
算法工作流程
K-means通过迭代优化实现聚类,其核心步骤为:
- 初始化中心:随机选择K个数据点作为初始质心(可优化)
- 分配样本:计算每个点到质心的距离,分配到最近簇
- 更新质心:重新计算各簇样本均值作为新质心
- 迭代收敛:重复2-3步直至质心变化小于阈值或达到最大迭代次数
数学表示
目标函数(SSE)是算法优化的核心:![]()
其中:
- Ci 表示第i个簇
- μi 是该簇质心
- ∥x−μi∥ 为欧氏距离
关键点:K-means本质是通过迭代最小化SSE实现聚类。算法复杂度为O(n⋅K⋅t),其中n为样本数,K为簇数,t为迭代次数。
距离度量选择
虽然默认使用欧氏距离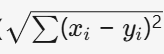 但可根据数据类型替换为:
但可根据数据类型替换为:
- 曼哈顿距离:
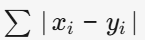 (适用于高维稀疏数据)
(适用于高维稀疏数据) - 余弦相似度:
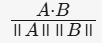 (适用于文本向量)
(适用于文本向量)
三、API参数深度解析(sklearn.cluster.KMeans)
掌握API参数是模型效果的关键保障:
| 参数 | 默认值 | 说明 | 调优建议 |
|---|---|---|---|
n_clusters | 8 | 聚类簇数K | 通过肘部法则确定 |
init | 'k-means++' | 初始化方法 | 优先选'k-means++'避免局部最优 |
n_init | 10 | 不同初始化次数 | 增大值提升稳定性,但增加计算量 |
max_iter | 300 | 最大迭代次数 | 高维数据建议增加到500 |
tol | 1e-4 | 收敛阈值 | 值越小精度越高但可能不收敛 |
algorithm | 'auto' | 算法实现 | 大数据选'elkan'提升速度 |
关键参数实践:
# 优化后的参数设置示例 from sklearn.cluster import KMeans model = KMeans(n_clusters=5, init='k-means++', n_init=20, max_iter=500,tol=1e-5,random_state=42 )
属性解析
labels_:样本所属簇标签cluster_centers_:质心坐标矩阵inertia_:当前SSE值(核心评估指标)
四、实战案例:酒聚类
import numpy as np
import pandas as pd
from matplotlib import pyplot as plt
from sklearn import metricsbeer = pd.read_table("data.txt",sep=' ',encoding='utf8',engine='python')
X=beer.iloc[:,1:]from sklearn.cluster import KMeans
scores=[]
K=[2,3,4,5,6,7,8,9]
for i in K:model = KMeans(n_clusters=i)model.fit(X)labels = model.labels_ #获取分类之后的标签score = metrics.silhouette_score(X,labels) #轮廓系数,可用来评价模型性能scores.append(score)best_K=K[np.argmax(scores)]
print('最佳K值',best_K)modle=KMeans(n_clusters=best_K)
modle.fit(X)
labels = modle.labels_
print('轮廓系数:',metrics.silhouette_score(X,labels))fig = plt.figure(figsize=(10, 8))
fig = plt.axes(projection="3d")# 绘制散点图(颜色映射和大小渐变)
scatter = fig.scatter(xs=X.iloc[:,0],ys=X.iloc[:,1],zs=X.iloc[:,2],c=labels, # 按聚类结果着色# cmap='viridis', # 使用色图映射alpha=0.8,s=50)# 设置标签和标题
fig.set(xlabel='X Axis', ylabel='Y Axis', zlabel='Z Axis',title='3D Scatter Plot with Color Gradient')
plt.show()五、模型评价:超越准确率的评估体系
无监督学习需依赖内部评价指标:
| 指标 | 公式 | 评估目标 | 范围 | 应用场景 |
|---|---|---|---|---|
| 轮廓系数 | max(a,b)b−a | 样本归属合理性 | [-1, 1] | 非凸簇评估 |
s_score = silhouette_score(X, labels) # 越接近1越好
print(f"轮廓系数: {s_score:.2f}")六 K值选择策略
from sklearn.cluster import KMeans
scores=[]
K=[2,3,4,5,6,7,8,9]
for i in K:model = KMeans(n_clusters=i)model.fit(X)labels = model.labels_ #获取分类之后的标签score = metrics.silhouette_score(X,labels) #轮廓系数,可用来评价模型性能scores.append(score)best_K=K[np.argmax(scores)]
print('最佳K值',best_K)给出几个K值,循环带入模型,保存轮廓系数,最后根据最优的轮廓系数找出最佳K值。